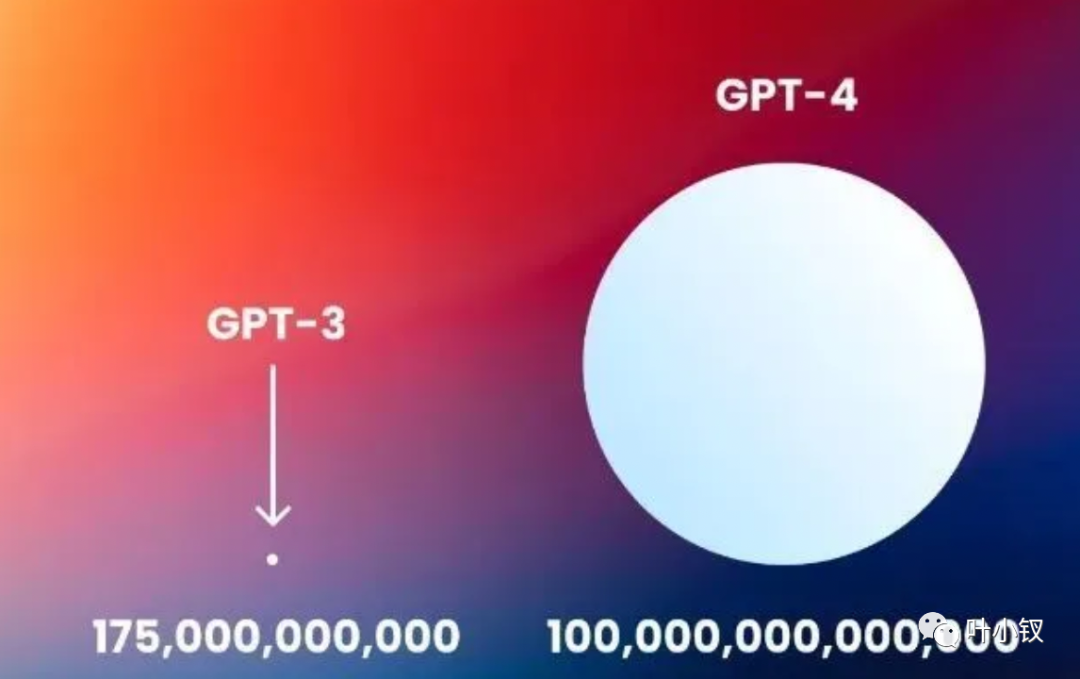
目前大火的ChatGPT用的是GPT3.5,GPT 3 有1750 亿参数,而接下来的GPT4 的参数高达100 万亿。

一般情况下,大脑约有 800-1000 亿个神经元(GPT-3 的数量级)和大约 105 万亿个突触。GPT-4 将拥有与大脑的突触一样多的参数,虽然还有很多卡点,但这很惊人...
参考资料:
目前大火的ChatGPT用的是GPT3.5,GPT 3 有1750 亿参数,而接下来的GPT4 的参数高达100 万亿。
一般情况下,大脑约有 800-1000 亿个神经元(GPT-3 的数量级)和大约 105 万亿个突触。GPT-4 将拥有与大脑的突触一样多的参数,虽然还有很多卡点,但这很惊人...
参考资料:
 全部评论: 0 条
全部评论: 0 条