https://github.com/Boris-code/feapder
- feapder是一款上手简单,功能强大的Python爬虫框架,内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。
- 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。
- 更有功能强大的爬虫管理系统feaplat为其提供方便的部署及调度。
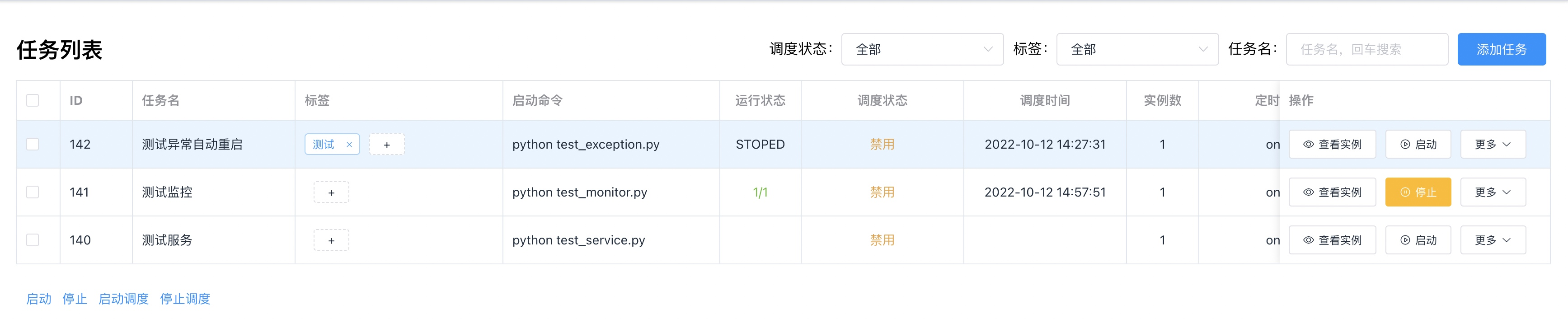
https://feapder.com/#/feapder_platform/feaplat 爬虫管理页面
import feapder
class FirstSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
FirstSpider().start()
 全部评论: 0 条
全部评论: 0 条