这是一个推荐系统的增量学习算法库,支持实时学习和批量实时学习,pip安装,非常简单的就能引入到需要推荐的项目中,而且效果还不错比较稳定。
pip install cf-stephttps://github.com/dpoulopoulos/cf_step
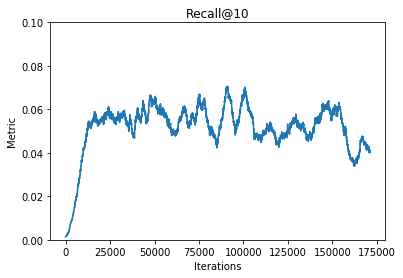
这是一个推荐系统的增量学习算法库,支持实时学习和批量实时学习,pip安装,非常简单的就能引入到需要推荐的项目中,而且效果还不错比较稳定。
pip install cf-stephttps://github.com/dpoulopoulos/cf_step
 全部评论: 0 条
全部评论: 0 条