Ultravox 开源项目详细介绍及其特色
项目概述
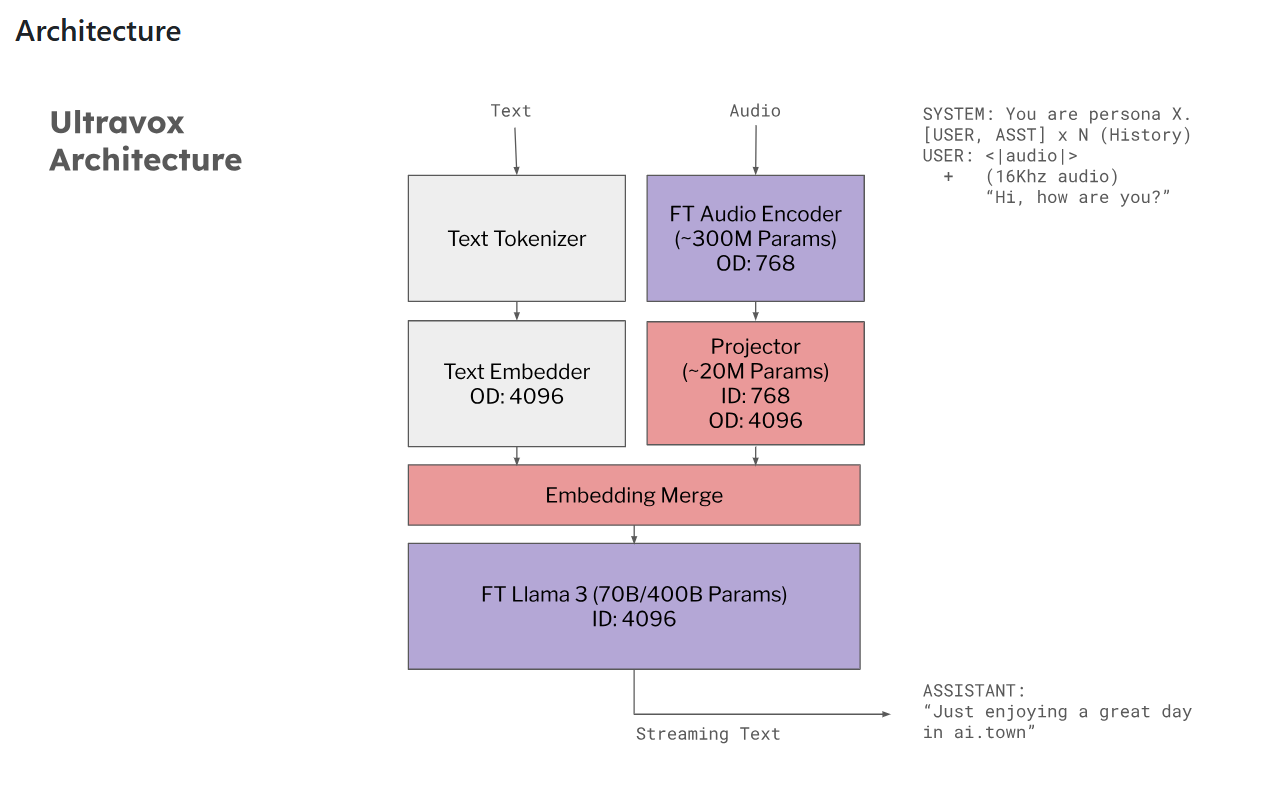
Ultravox 是一个开源的多模态大语言模型(LLM),专为实时语音处理而设计。它能够直接理解文本和人类语音,无需依赖单独的音频语音识别(ASR)阶段。这一特性使得 Ultravox 在响应速度和集成效率上具有显著优势。该模型通过多模态投影器技术将音频数据转换为高维空间,从而实现对语音内容的高效处理 [2]。
主要特点
端到端多模态处理
- Ultravox 是一款端到端的多模态大模型,可以直接处理文本和语音输入。它避免了传统系统中需要先进行语音识别再进行自然语言处理的复杂流程,大大减少了延迟时间。
超快响应时间
- 响应时间约为150毫秒,确保了用户可以获得几乎即时的反馈,适用于需要快速响应的应用场景,如智能客服、虚拟助手等 [1]。
集成高效
- 一体化的语音与文本处理机制大幅减少了延迟,提高了系统的整体性能。这种高效的集成方式使得 Ultravox 在实际应用中表现出色 [11]。
扩展性强
- 基于强大的 Llama 3 模型,Ultravox 易于进一步训练和定制化,以适应不同的应用场景和需求。开发者可以根据具体需求对模型进行微调,提升其在特定任务上的表现。
支持多种输入格式
- Ultravox 可以处理多种输入格式,包括文字、图片和其他感官数据。这使得它不仅限于语音处理,还可以应用于更广泛的多模态交互场景 [7]。
开源特性
- 作为一个开源项目,Ultravox 提供了详细的文档和技术支持,方便开发者进行研究和开发。GitHub 上的代码库包含了项目的完整实现,并且社区活跃,提供了丰富的教程和示例代码 [6]。
技术细节
- 参数数量:不含嵌入的参数数量为30.95B,层数为64,注意力头数量为多个 [9]。
- 模型架构:基于预训练的 Llama3.1-70B-Instruct 和 whisper-large-v3-turbo 背骨,确保了模型的强大基础和广泛适用性 [28]。
- 优化技术:引入了多步调度(Multistep scheduling)和异步输出处理(Asynchronous output processing),优化了GPU的利用率并提高了处理效率,从而提高了整体吞吐量 [12]。
应用场景
- 智能客服:实时处理客户咨询,提供快速准确的回答,提升用户体验。
- 虚拟助手:支持语音指令和对话,帮助用户完成各种任务,如信息查询、日程管理等。
- 语言学习:通过实时语音反馈,帮助用户提高语言表达能力,纠正发音问题。
- 智能家居:控制智能设备,实现语音交互,提升家居自动化水平。
总之,Ultravox 以其独特的多模态处理能力和高效的实时响应特性,为语音处理领域带来了新的突破。作为开源项目,它也为广大开发者提供了一个极具潜力的研究和开发平台。
 全部评论: 0 条
全部评论: 0 条