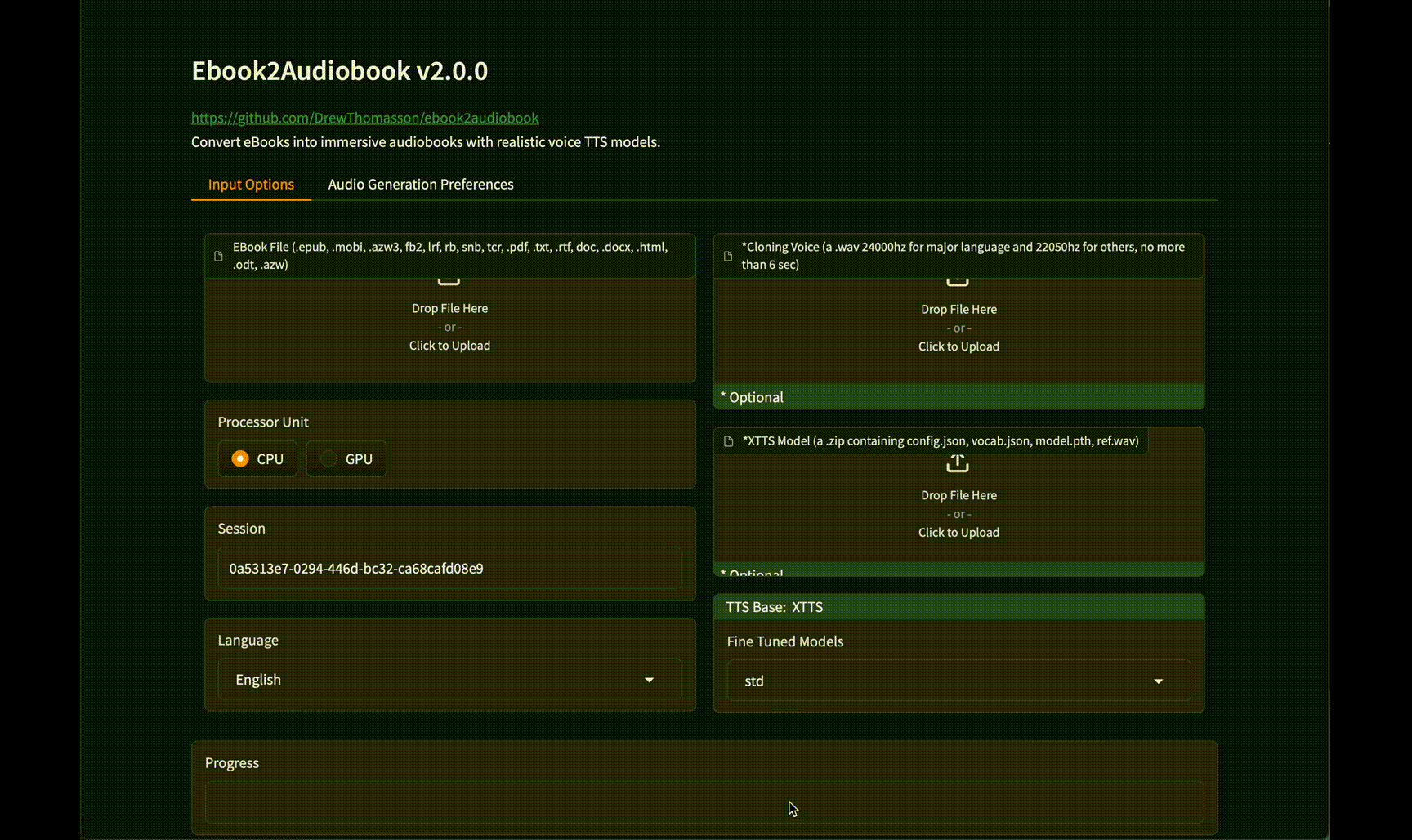
这个GitHub项目名为ebook2audiobook,由DrewThomasson创建,旨在将电子书(eBooks)转换为有章节和元数据的有声书(audiobooks),使用的是动态AI模型和声音克隆技术。该项目支持1,107种以上的语言。
以下是该项目的一些关键特性和使用方法:
关键特性
- 多语言支持:支持1124种语言的转换。
- 声音克隆:可以克隆特定的声音用于文本到语音(TTS)转换。
- 技术栈:使用Calibre、ffmpeg、XTTSv2、Fairseq等工具。
- 图形界面:提供了Gradio界面,方便直接转换。
- 批处理:支持批量转换电子书。
- 自定义模型:允许使用自定义模型进行转换。
使用方法
克隆项目:
git clone https://github.com/DrewThomasson/ebook2audiobook.git运行脚本:
- 直接转换模式:
python app.py --ebook 'path_to_ebook' - 图形界面模式:
python app.py
- 直接转换模式:
命令行选项:
--script_mode:强制脚本以NATIVE或DOCKER_UTILS模式运行。--share:启用公共可分享的Gradio链接。--ebook:指定要转换的电子书文件路径。--ebooks_dir:指定包含电子书的目录路径,用于批量转换。--voice:指定目标声音文件路径,用于TTS。--language:指定音频书转换的语言。--device:指定使用CPU还是GPU进行转换。--custom_model:指定自定义模型的路径。--temperature:模型的温度参数,影响创造性输出。--length_penalty、--repetition_penalty、--top_k、--top_p:这些参数影响音频生成的速度和输出的可靠性。--speed:语音生成的速度因子。--enable_text_splitting:启用文本分句。--fine_tuned:指定微调模型的名称。--version:显示脚本版本。
Docker使用方法
拉取Docker镜像:
docker pull athomasson2/ebook2audiobook创建输入和输出目录:
mkdir input-folder && mkdir Audiobooks运行Docker容器:
docker run -it --rm \ -v $(pwd)/input-folder:/home/user/app/input_folder \ -v $(pwd)/audiobooks:/home/user/app/audiobooks \ --platform linux/amd64 \ athomasson2/ebook2audiobook \ python app.py --headless --ebook /input_folder/YOUR_INPUT_FILE.TXT
其他信息
- Docker Compose:项目使用Docker Compose进行本地运行,可以通过设置
docker-compose.yml中的*gpu-enabled或*gpu-disabled来启用或禁用GPU支持。 - Google Colab:项目提供了在Google Colab上免费运行的指南。
- 模型库:项目提供了Hugging Face链接,用于查找已经微调的TTS模型。
这个项目为电子书到有声书的转换提供了一个强大的工具,特别是对于需要多语言支持和声音克隆功能的用户。
 全部评论: 0 条
全部评论: 0 条