Fish Speech 详细介绍
Fish Speech 是由 Fish Audio 团队开发的一款开源文本转语音(TTS)模型,旨在提供高质量、易用的语音合成解决方案。它不仅支持多语言(包括中文、日语和英语),还具备强大的声音克隆功能,能够在最少数据的情况下进行准确的语音复制。以下是关于 Fish Speech 的详细介绍:
1. 核心技术
Fish Speech 基于多种前沿的 AI 技术构建,主要包括:
- VQ-GAN:用于生成高质量的音频特征。
- Llama:用于处理自然语言理解。
- VITS:用于提高音色相似度和降低口胡现象。
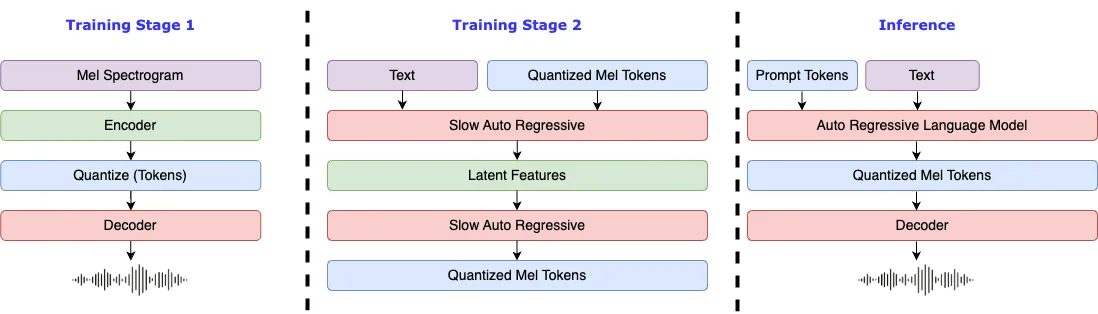
这些技术共同构成了 Fish Speech 强大的声音合成引擎,使其能够生成逼真自然的语音 [2]。
2. 功能特点
Fish Speech
- 零样本和少样本TTS:输入10到30秒的声音样本,生成高质量的TTS输出。
- 多语言和跨语言支持:支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
- 无需音素依赖:模型具有强大的泛化能力,不依赖于音素进行TTS。
- 高准确度:对于5分钟的英语文本,CER(字符错误率)和WER(单词错误率)低至约2%。
- 快速:在Nvidia RTX 4060笔记本电脑上实时因子约为1:5,在Nvidia RTX 4090上约为1:15。
- WebUI推理:基于Gradio的易用Web UI,兼容Chrome、Firefox、Edge等浏览器。
- GUI推理:提供PyQt6图形界面,与API服务器无缝协作,支持Linux、Windows和macOS。
- 部署友好:支持Linux、Windows和MacOS的原生推理服务器部署。
Fish Agent
- 端到端集成:自动集成ASR(自动语音识别)和TTS部分,无需插入其他模型。
- 音色控制:可以使用参考音频来控制语音的音色。
- 情感表达:模型可以生成具有强烈情感的语音。
3. 部署灵活性
Fish Speech 提供了高度的自定义和灵活性,允许用户根据个性化需求进行设置。无论是通过在线平台还是本地部署,用户都可以轻松体验AI语音合成的乐趣。特别是对于需要使用GPU进行模型训练和推理的用户,安装 NVIDIA Container Toolkit 后可以拉取并运行 Fish Speech Docker 镜像,极大地方便了开发者的使用 [4]。
4. 性能与资源需求
Fish Speech 的最新版本(如1.5版)在性能上有了显著提升,仅需4GB显存即可流畅运行,使得更多用户能够在普通硬件上体验到高效的语音生成工具。此外,Fish Speech 支持零样本和少量样本(10到30秒的音频样本)的声音克隆,进一步降低了使用门槛 [6]。
5. 应用场景
Fish Speech 广泛应用于多个领域,包括但不限于:
- 客户服务自动化:通过定制化语音模型提高客户互动体验。
- 媒体工作流程优化:为视频、广播等媒体内容提供高质量的配音服务。
- 教育内容个性化:根据不同学习者的需求生成个性化的教学语音。
6. 开源与社区支持
作为一个开源项目,Fish Speech 在 GitHub 上拥有活跃的社区支持,用户不仅可以获取最新的代码和技术文档,还可以参与讨论和贡献代码。此外,Fish Speech 的开发者团队定期发布更新,不断改进模型的稳定性和功能,确保用户始终能够使用到最先进、最稳定的版本 [27]。
总结
Fish Speech 是一款集成了多项先进技术的开源 TTS 工具,以其高质量的语音合成、多语言支持和灵活的部署方式赢得了广泛的认可。无论是个人开发者还是企业用户,都可以通过 Fish Speech 实现高效、低成本的语音合成解决方案。
如果您对 Fish Speech 有任何疑问或需要进一步的帮助,请随时联系开发者社区或参考官方文档。
 全部评论: 0 条
全部评论: 0 条