FireCrawl 详细介绍
FireCrawl 是一款由 Mendable.ai 开发的创新性 Web 爬虫工具,旨在将整个网站转换为大语言模型(LLM)友好的数据。它能够抓取任何网站的所有可访问子页面,并将其内容转换为干净的 Markdown 或结构化数据格式。以下是 FireCrawl 的详细介绍:
主要功能
无需站点地图:
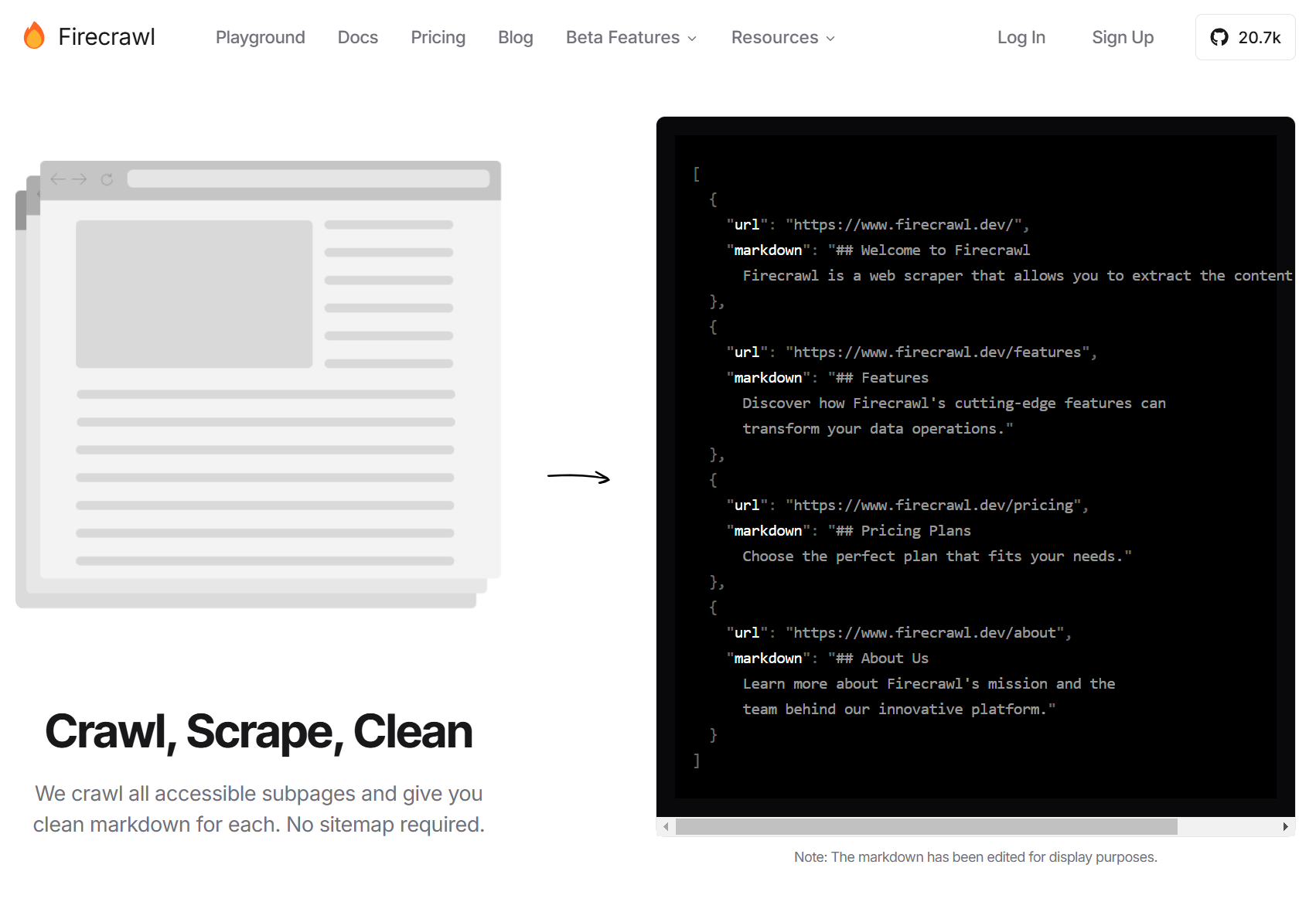
- FireCrawl 不需要依赖站点地图即可抓取网站的所有可访问子页面,这使得它在处理复杂和动态生成的内容时表现出色 [2]。
自动遍历与数据提取:
- FireCrawl 从给定的网页开始,自动找到并访问该网站上的所有其他页面。它会提取每个页面的主要内容,去掉广告和其他不需要的元素,确保数据的纯净度 [3]。
JavaScript 支持:
- 通过模拟浏览器的方式或其他技术执行 JavaScript 代码,FireCrawl 能够访问并抓取动态生成的内容,适用于复杂的、动态的网站 [7]。
LLM Extract 功能:
- FireCrawl 特别上线了 LLM Extract 功能,利用大语言模型快速完成网页数据的提取,从而转换为 LLM-ready 数据,非常适合用于 AI 训练和数据提取 [1]。
本地化部署支持:
- FireCrawl 支持本地化部署,可以在本地环境中运行,提供了更高的灵活性和安全性 [8]。
API 服务:
- FireCrawl 提供 API 接口,用户只需输入 URL 即可启动爬取任务。它会遍历所有可访问的子页面,并为每个页面提供干净的 Markdown 或结构化数据 [21]。
使用场景
- AI 训练数据准备:FireCrawl 可以帮助开发者快速获取大量高质量的训练数据,用于训练大语言模型。
- 内容提取与分析:适合需要从多个网站提取内容并进行分析的场景,如市场调研、竞争情报等。
- 自动化工作流:结合其他工具(如 Make),可以实现全自动撰写博客文章引流等功能 [9]。
安装与使用方法
安装:
- 从 GitHub 获取 FireCrawl 的源码并安装必要的依赖项 [11]。
基本使用:
- 使用
scrape_url方法抓取单个 URL 的内容,并以字典形式返回抓取的数据 [13]。
- 使用
API 使用:
- 通过 API 请求发送 URL,FireCrawl 将返回抓取后的 Markdown 或结构化数据。
性能与优势
- 高可靠性:针对不同类型网站,FireCrawl 的抓取能力比其他爬虫可靠性高 40% [10]。
- 易用性:操作简单,易于集成到现有的开发流程中。
- 开源:FireCrawl 是一个开源项目,用户可以根据需求进行自定义和扩展。
示例应用
- 与 OpenAI 实时 API 结合:创建低延迟、多模态对话式体验,实时获取和交互网页内容 [16]。
- LangChain 集成:用于 Retrieval-Augmented Generation (RAG) 管道,增强自然语言处理应用 [22]。
总结来说,FireCrawl 是一款强大且灵活的 Web 爬虫工具,特别适合需要高效、精准地从网站提取数据并用于 AI 应用的开发者。其丰富的功能和良好的性能使其成为现代数据提取任务的理想选择。
 全部评论: 0 条
全部评论: 0 条