MemoRAG是什么?
MemoRAG(Memory-Enhanced Retrieval-Augmented Generation)是一种由长期记忆增强的检索增强生成框架,旨在改进传统RAG(Retrieval-Augmented Generation)模型的性能和适用范围。它通过引入全局记忆能力,能够处理更复杂的查询和更大的数据集,特别是在面对长文本和模糊查询时表现出色。
主要原理
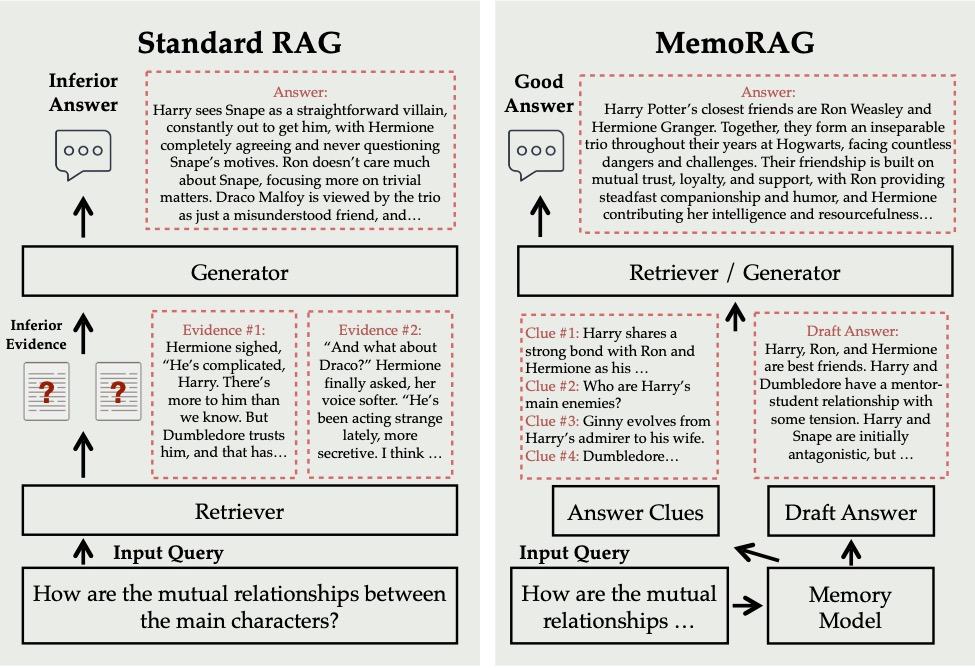
MemoRAG的核心原理是通过双系统架构来实现高效的检索和生成:
全局记忆模块:
- 使用轻量但高效处理超长文本的LLM(大型语言模型)作为全局记忆模块。这个模块能够处理长达百万词的单上下文数据,为处理大量数据提供了强有力的支持 [4]。
- 全局记忆模块不仅存储当前对话的信息,还能记住跨不同交互的关键事实、事件或主题,从而在后续查询中提供更准确的背景信息。
表达能力强的生成模块:
- 采用一个表达能力更强的LLM来生成最终的回答。当任务提出时,记忆模块会生成一系列关键线索,这些线索帮助模型更有针对性地进行信息检索和内容生成 [6]。
基于记忆的线索生成:
- MemoRAG首先根据用户的问题和已有知识生成一系列关键线索,这些线索用于指导后续的信息检索过程。这种机制使得模型在处理模糊查询和非结构化知识时更加有效 [2]。
与传统RAG框架的区别
相比于传统的RAG框架,MemoRAG具有以下几个显著优势:
长期记忆能力:
- 传统RAG模型主要依赖于外部数据库中的即时检索结果,而MemoRAG则通过长期记忆模块保留了整个数据集的全局记忆。这使得MemoRAG能够在多次交互中积累和利用历史信息,提高回答的准确性和连贯性 [19]。
处理复杂查询的能力:
- 对于模糊查询表述和高度非结构化的知识,MemoRAG的表现更为出色。其基于记忆的线索生成机制能够更好地理解和处理复杂场景,从而提供更精准的答案 [6]。
更高的可优化性和灵活性:
- MemoRAG具备高度的可优化性和灵活性,可以根据不同的应用场景进行调整和优化。例如,在文献管理系统中,它可以自动帮用户整理、分类和检索文献;在企业环境中,可以集成到知识管理系统中,提升工作效率 [5]。
总结来说,MemoRAG通过引入长期记忆模块和双系统架构,显著提升了检索增强生成模型的性能和适用范围,特别是在处理复杂查询和大规模数据时表现尤为突出。
 全部评论: 0 条
全部评论: 0 条