1. 背景
关联词:限频、访问控制、爬虫、反爬虫、WAF、长亭、雷池
对于一些自动的 bot 或者恶意的爬虫,其访问网站的频率大、时间长,如果打开云服务器的管理后台,往往会发现网络的大部分流量都集中在一个或几个的 IP 上。对于这些情况其实都可以以一个很简单的手段实现,那就是在服务器中对访问IP限频。
但是对于访问IP的限频功能通常与业务逻辑关系不大,开发者通常不太想要去自己维护一个IP访问频次表,同时在分布式、并发等条件下手动维护所有访问者的信息有着很大的开发成本。
长亭的雷池 WAF 正好解决了这一系列问题, 雷池提供了限频、端口转发、手动IP黑白名单等功能,以及其核心功能——防御 Web 攻击。
2. 安装雷池
官网提供了在线安装、离线安装、牧云助手安装三种方式,本文不再赘述,详情可以查看:
https://waf-ce.chaitin.cn/docs/guide/install
3. 登录雷池
雷池采用了 OTP 手段进行登录鉴权, 简单来说就是通过腾讯身份验证器等软件,向登录页面输入手机软件上生成的动态密码(约15s 会更新一次密码)即可。
3.1 软件扫码绑定

扫码后即绑定,可以在首页看到动态密码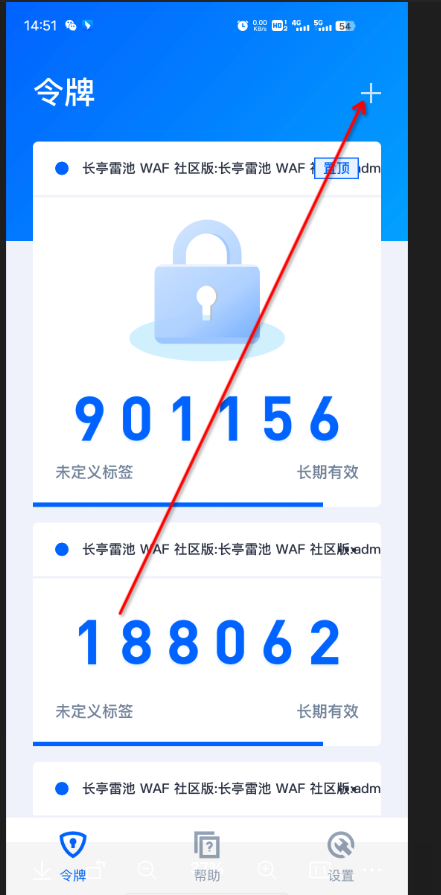
3. 2 输入口令密码

3.3 进入雷池管理界面

4. 配置站点和限频功能
4.1 雷池站点配置
雷池的站点配置功能比较齐全,包括自动上传 TLS 证书、私钥,指定多个转发端口等,不需要开发者自己配置 nginx 转发
4.2 配置限频功能
具体的封禁策略可以进行自定义,推荐为 10 s,100 次 ,封禁 10分钟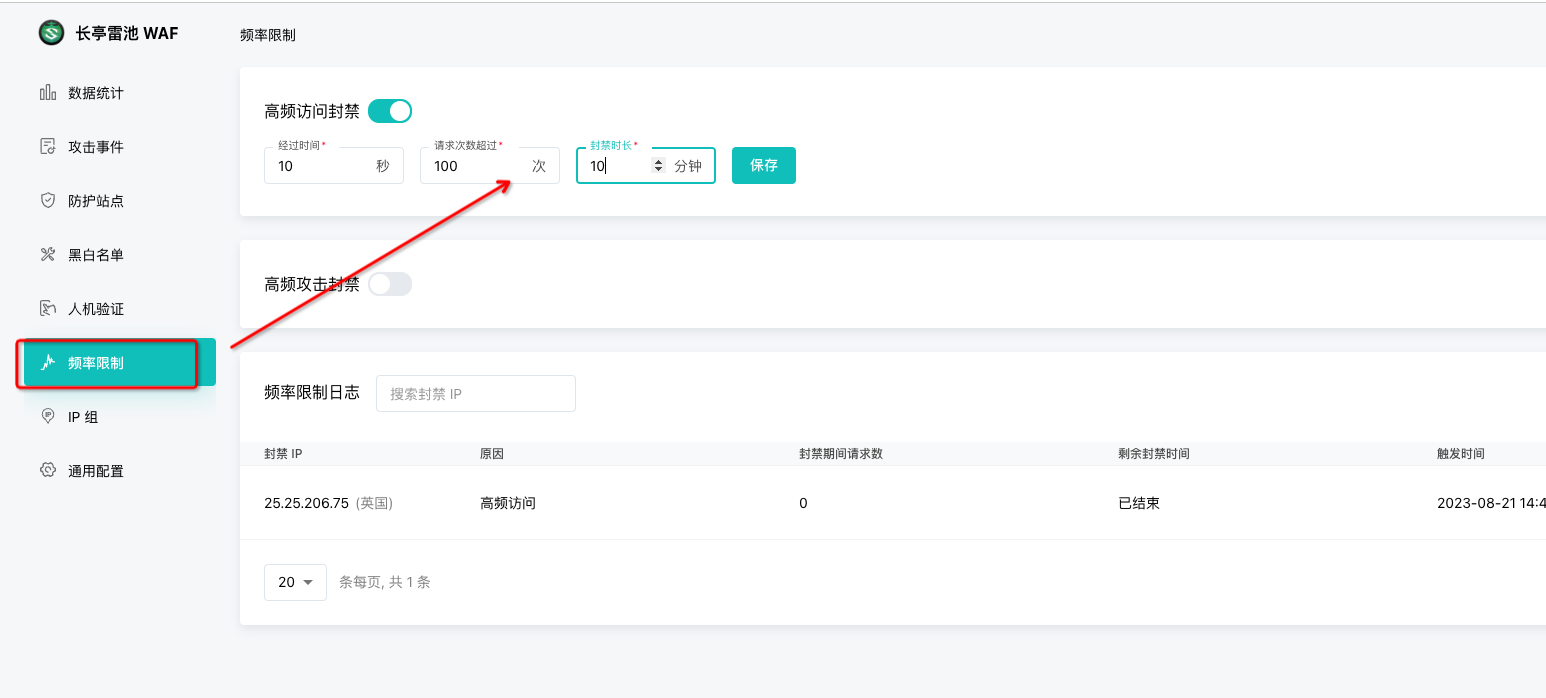
PS:如果是自己测试,或者发现误报的,可以手动解除封禁
5. 测试及其他
5.1 测试
后台准备了一个简单的服务器,提供一个hello的接口,带有一个a的参数
简单编写测试的爬虫代码:
def send_request(url,request_method="GET",header=None,data=None):
try:
if header is None:
header=Config.get_global_config().header
response = requests.request(request_method, url, headers=header)
return response
except Exception as err:
print(err)
pass
return None
if __name__ == '__main__':
# config=Config.get_global_config()
# print(config.header) # send_request(header="asad")
for i in range(0,100):
str = random.choice('abcdefghijklmnopqrstuvwxyz')
resp = send_request("http://a.com/hello?a="+str)
print(resp.content)
打印值
b'{"a":"u"}'
b'{"a":"m"}'
b'{"a":"y"}'
b'{"a":"o"}'
b'<!DOCTYPE html>\n\n<html lang="zh">\n <head>\n .... #后续是一串很长的 HTML 文本
此时重新访问页面可以发现已经被拦截了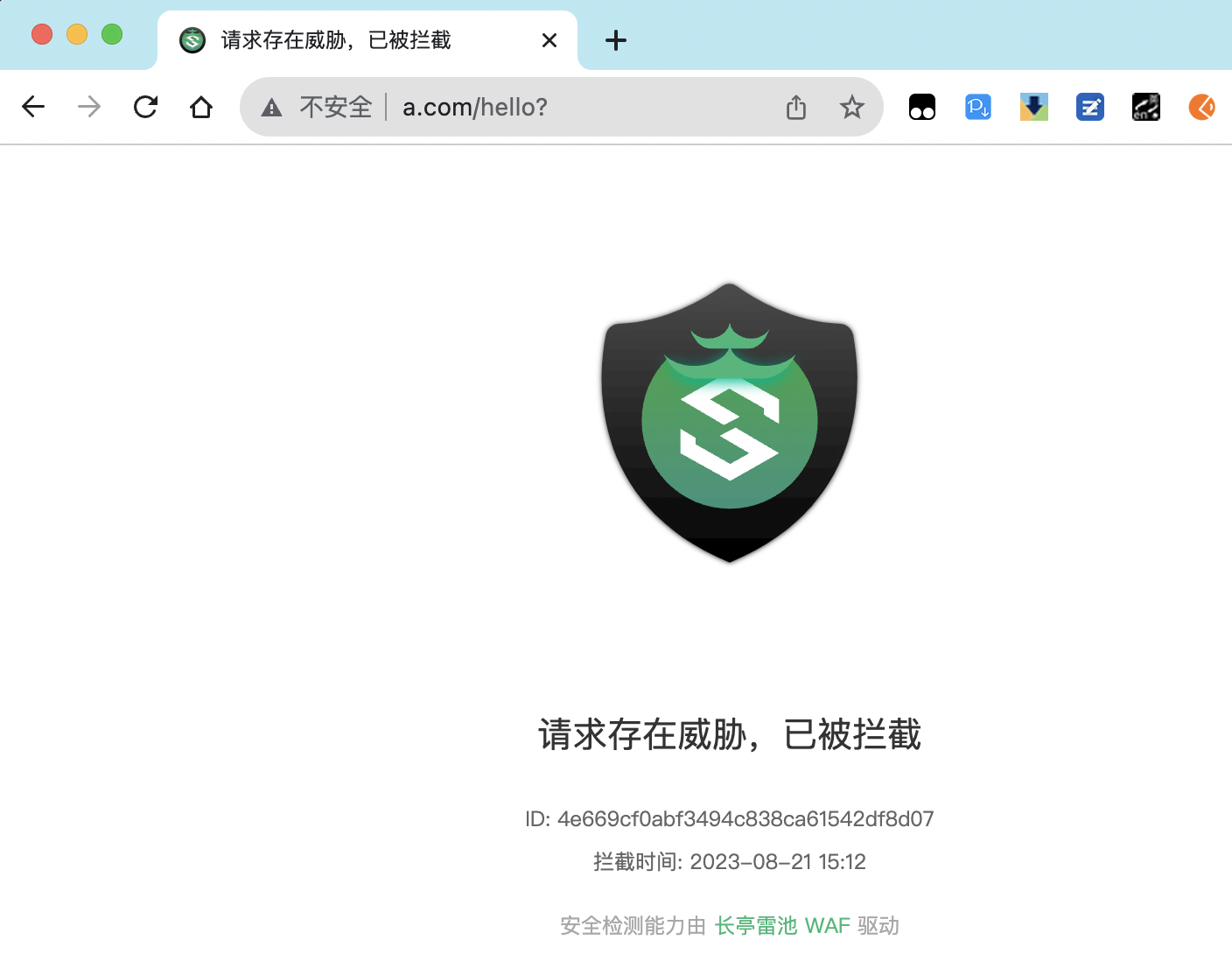
5.1 有些爬虫比较狡猾,伪造X-Forwarded-For请求头怎么办
雷池可以直接在 ‘通用配置’->‘源 IP 获取方式’->选中‘从网络连接中获取’
表示从 TCP 连接中获取 Source IP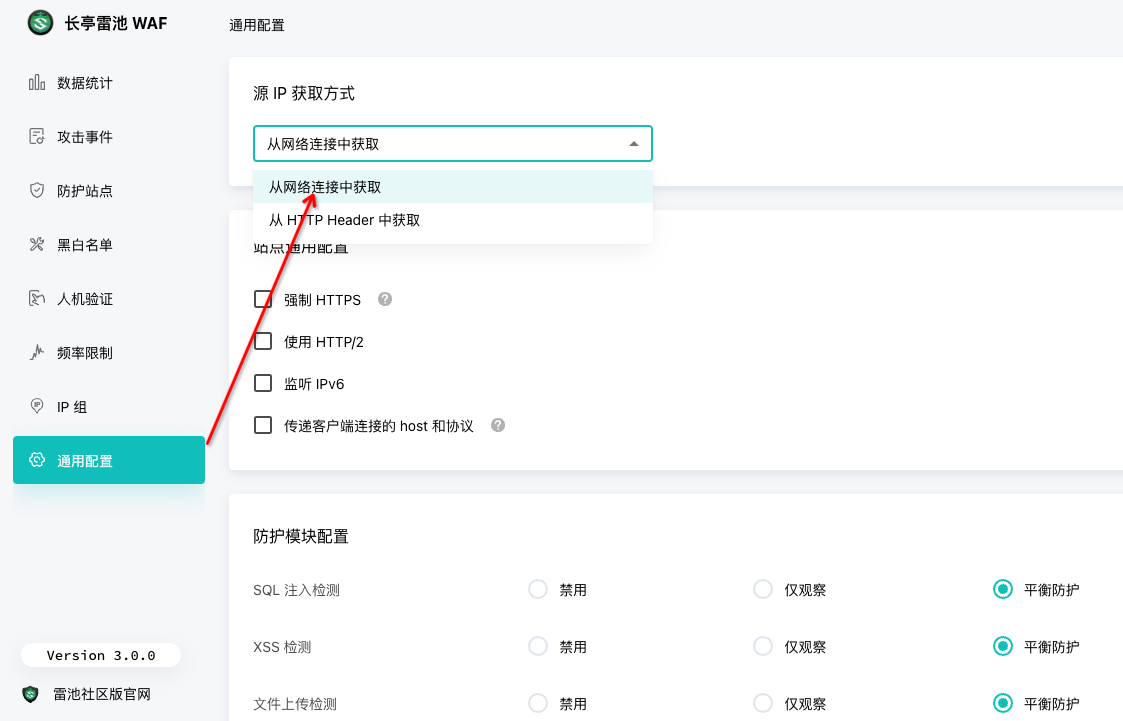
如果你要问‘如果爬虫十分狡猾,伪造了 TCP 的 Source IP 字段怎么办?’
好吧,由于伪造了TCP头信息,由于 HTTP 基于 TCP 的握手会直接失败, 爬虫本身已经失去了爬取信息的能力,访问请求也会在经过 nginx 时被丢弃。
 全部评论: 0 条
全部评论: 0 条