https://github.com/ztxz16/fastllm
支持python安装,关键是只需2行代码,原来程序不需要做任何改动!正好最近给公司部署和开发了chatglm-6B,这就叫刚想打瞌睡就有人递枕头
# 这是原来的程序,通过huggingface接口创建模型
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code = True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code = True)
# 加入下面这两行,将huggingface模型转换成fastllm模型
from fastllm_pytools import llm
model = llm.from_hf(model, tokenizer, dtype = "float16") # dtype支持 "float16", "int8", "int4"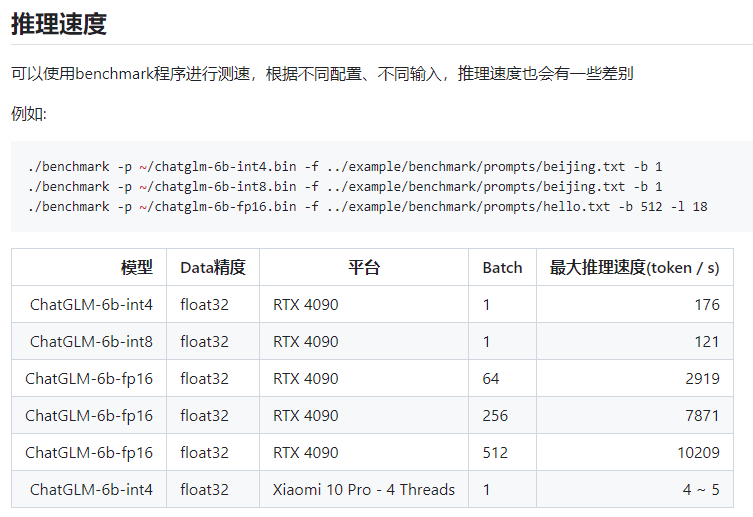
https://github.com/ztxz16/fastllm/blob/master/docs/benchmark.md
 全部评论: 0 条
全部评论: 0 条